
SpadEx PALM: Pluggable Agentic Last Mile
Enterprise Data Sovereignty Meets Token-efficient Native-Agentic Intelligence

The Modern Enterprise Predicament
Today, Modern enterprises face a severe bottleneck when deploying language models (VLM/SLM/LLM) powered agents on sensitive data: the compromise between cloud-scale intelligence and data privacy. Moving proprietary financial documents, HR records, or legal contracts to external cloud APIs poses massive compliance risks, while running pure local models often sacrifices multi-step reasoning capabilities. Cost-efficiency on both these ends are the current nightmares CIOs face. The dreadful analogical questions that haunt enterprises everyday - Should I rent a luxury sports-car for my grocery shopping or own a mini-van for commute. Is there an option in-between like leasing an EV?
Yes - SpadEx’s PALM (Pluggable Agentic Last Mile) solves this problem through a hybrid edge-cloud infrastructure platform. By decoupling public orchestration from private inference, PALM delivers advanced multi-agent capabilities while guaranteeing that private customer data never leaves the sovereign boundary. And guess what - PALM does that in the most economical fashion offloading only a part of the inference to cloud AI APIs and using that understanding at runtime to guide the rest of the local inference. Analogically, PALM applies the understanding of “how to infer” rather than “what to infer” to empower private LLMs with the accuracy boost staying token economical.
The Architecture: Three-LLM Pipeline
PALM coordinates intelligence across three distinct abstraction layers to optimize both processing efficiency and total privacy. The PALM agents are designed to use the best toolset for the most important roles in an inference run.
Agent 1: The Reference LLM (Cloud): Processes a publicly shareable, non-sensitive sample document alongside user instructions to generate structural reasoning and expected output formatting. Bypass Mode: Users can inject pre-computed reasoning directly to eliminate cloud LLM costs entirely.
Agent 2: The CodeGen LLM (Cloud): Acts as the planner. It translates the high-level prompt into a structured, multi-step execution plan and generates a temporary Python agent composed of focused sub-agents. It operates strictly on structural logic and never witnesses private data.
Agent 3: The Adapt VLM (Local Edge): A lightweight, high-efficiency local vision-language model running inside a secure container on the customer’s hardware (supporting CPU, GPU, or ARM architectures). Adapt executes the custom code generated by the CodeGen LLM to analyze private documents locally, streaming tokens directly to the user application at $0.
PALM in Action: A Deep Dive into the User Interface and Live Execution
To demonstrate how the three-LLM pipeline shifts processing workloads away from costly cloud APIs while protecting data privacy, let’s trace a live document extraction session using the PALM user interface.
Interface Layout and Setup
The application interface splits its configuration parameters across a scannable sidebar to cleanly separate public framing from local execution:
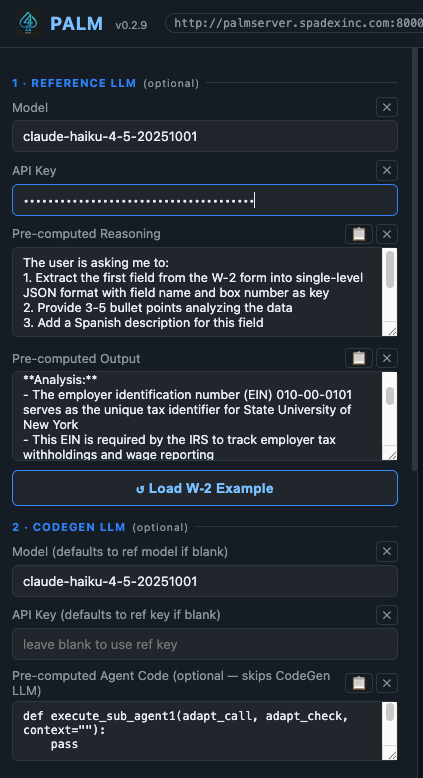
Model and Agent Selection: As seen here, the left panel configures the cloud intelligence layers (Section 1: Reference LLM and Section 2: CodeGen LLM). Here, Claude Haiku is specified to manage task planning and few-shot reasoning blueprinting without ever witnessing private enterprise assets. Pre-computed reference and CodeGen can be loaded for similar prompts and input to avoid repetitive token costs.
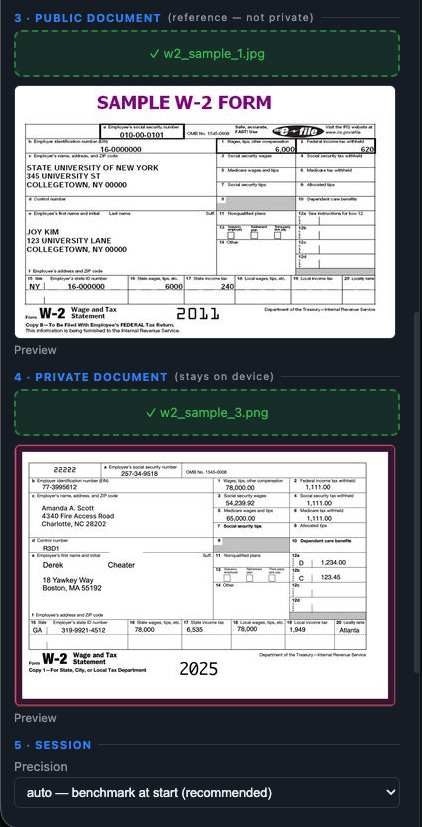
Dual-Document Boundary Separation: As shown here, the document upload zones are strictly isolated. A non-sensitive public file is loaded into Section 3 to establish the contextual reference schema, while the actual sensitive file stays firmly placed in Section 4 (Private Document), structurally locked to the local environment.
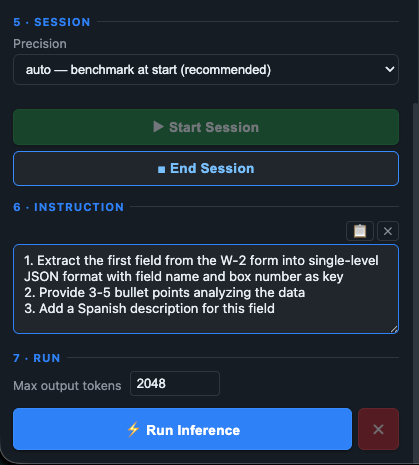
Precision and Execution Control: This image highlights the session execution deck (Section 5, 6, and 7). The prompt instructs PALM to perform a multi-step operation: extract a specific data field into a single-level JSON structure, output 3–5 core analytical bullet points, and translate the data description into Spanish.
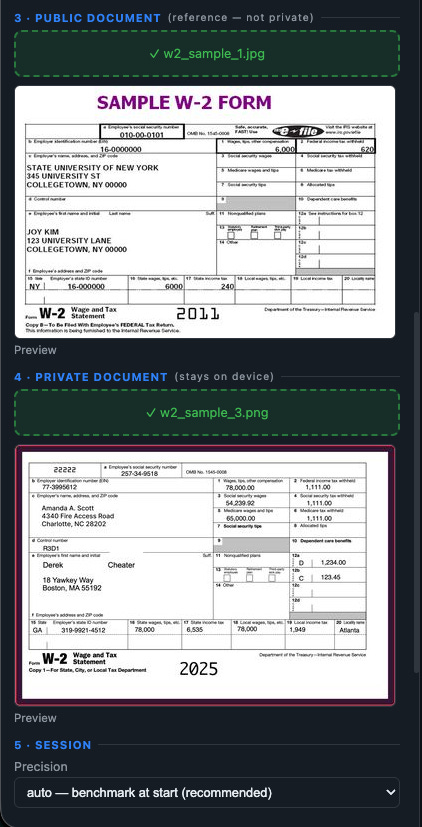
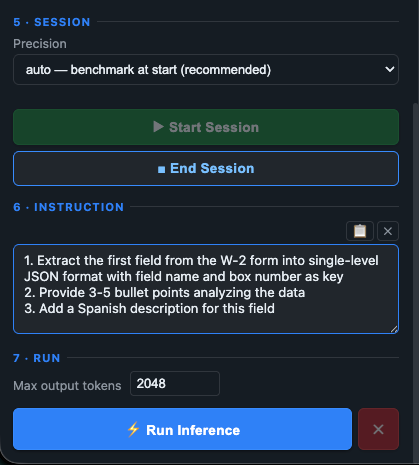
Data Disclosure Note: The file used in this private document workspace is an example of a W-2 form for illustrative purposes only, sourced directly from Resistant AI.
Live Pipeline Run & Telemetry Tracking
The runtime sequence captured in the video highlights PALM’s automated orchestration loop and its transparent telemetry architecture:
Phase 1 — Planning & Reference Creation: Upon clicking Run Inference, PALM passes the instruction and public sample to the cloud Reference LLM to create structural examples. The cloud CodeGen LLM then builds a dynamic Python script containing localized sub-agent stubs.
Phase 2 — Isolated Local Execution: The generated orchestrator code executes locally in a secure sandbox on the client’s machine. The local Adapt VLM reads the private document natively via high-performance hardware acceleration (as marked by the live indicator in the telemetry panel).
Phase 3 — Real-Time Telemetry and Cost Savings: As the local model processes the data step-by-step, the chat interface displays live, streaming output bubbles corresponding to each sub-agent execution. Crucially, the final telemetry metrics confirm an input token count of 1,479 and an output token count of 72 entirely mapped to the Local In/Out counters.
This direct visual feedback proves that after the initial minimal cloud handshake for code structure generation, the entire operational burden is carried on-premise—delivering advanced agent logic at a flat $0 marginal token cost.
Core Commercial Moats
1. Zero-Trust Data Sovereignty
Private documents and inference data remain strictly on-device inside a local Docker container. Furthermore, PALM utilizes an ephemeral lifecycle model: model weights are streamed on-demand per session and are automatically evicted from both system VRAM and storage upon session termination, preventing persistent data footprints.
2. Measurable Framework Efficiency
The underlying commercial value of PALM stems from the extreme efficiency of the Adapt and PALM frameworks working in tandem. Complex, multi-page or non-standard documents that typically choke out simple vision prompts are effortlessly parsed because PALM automatically splits tasks into localized sub-agent operations.
3. Dynamic Three-Tier Resiliency
Unlike fragile extraction scripts, PALM features a built-in automated verification layer. The generated orchestrator continually runs quality evaluations between steps. If a sub-agent execution fails, PALM instantly classifies the error:
Formatting Failures: Routes to a lightweight reformat sub-agent utilizing a blank image buffer, bypassing a heavy document re-scan.
Semantic Failures: Retries a full context-injected scan on the Adapt engine locally.
Contextual Failures: Re-invoke CodeGen to “self-heal” and recuperate chain-of-thought boosting context intelligence.
4. Insulating Against the Incoming Token Explosion
As enterprise documents scale into multi-page PDF behemoths, relying on cloud APIs creates a linear financial trap: more data equals exponentially higher token bills. PALM provides an economic firewall against this future. Because the local Adapt VLM processes the heavy, token-dense document content natively on-device, your local token consumption scales at a flat $0 marginal cost. Cloud LLMs are strictly leveraged for low-token, high-leverage architectural blueprinting. You get the infinite scalability of processing massive data loads without the accompanying line-item explosion on your monthly cloud invoice.
5. Pluggable Infrastructure Flexibility
PALM is engineered as a set of highly flexible software components rather than a rigid, hardware-locked vertical stack. The server and client layers scale dynamically to match available compute resources, executing optimized precision modes based on automatic real-time hardware benchmarking at runtime.
The Strategic Bottom Line: SpadeX PALM provides enterprises with the exact reasoning and orchestration benefits of advanced cloud-scale AI pipelines, while structurally guaranteeing total isolation for their most sensitive physical data assets.
Ready to Evaluate PALM?
Stop choosing between infinite cloud bills and compromised AI intelligence. Experience a sovereign, pluggable AI framework that aligns perfectly with your enterprise compliance and fiscal budgets.
Request a Private Technical Briefing: Schedule a deep dive into the PALM deployment architecture with our engineering team.
Deploy a Local Proof-of-Concept (PoC): See PALM parse your most complex, sensitive document types on your own secure infrastructure in under an hour.
Get in Touch - Book a Demo
Cost Estimation Disclaimer:
Cost estimations and annual projections featured in this whitepaper and within the PALM telemetry dashboard are calculated using public, third-party API pricing metrics current as of June 2026. Projections are specifically modeled using Anthropic’s published rates for the user-selected model tier.
Independent Benchmarks: These financial comparisons represent independent architectural benchmarks calculated by SpadEx Inc.. They do not represent an official quote, pricing guarantee, or commercial endorsement by Anthropic.
Variable Operational Factors: Actual production costs will vary dynamically depending on:
Individual enterprise volume agreements.
Token density variations across unique, non-standard user document types.
Third-party vendor API pricing modifications over time.
All product names, logos, and brands are property of their respective owners. Use of these names does not imply affiliation or endorsement.